
Chapter 3. Amino Acids & Proteins
Chapter Outline
- 3.1 Biological Macromolecules
- 3.2 Types and Functions of Proteins
- 3.3 Amino Acids
- 3.4 Protein Structure
Introduction
We will now begin our tour of the four major types of macromolecules found in living organisms. The first type of molecule, proteins, are molecular machines that do the work of cells. They have a huge variety of structure and function. But before we delve into how protein structure relates to protein function, we first have to discuss macromolecules.
3.1 | Biological Macromolecules
Learning Objectives
By the end of this section, you will be able to:
- Name the four major classes of biological macromolecules.
- Understand the synthesis of macromolecules.
- Describe dehydration synthesis and hydrolysis reactions.
Biological macromolecules are large molecules, necessary for life, that are built from smaller organic molecules. There are four major classes of biological macromolecules: carbohydrates, lipids, proteins, and nucleic acids. Each is an important cell component and performs a wide array of functions. Combined, these molecules make up the majority of a cell’s dry mass (recall that water makes up the majority of its complete mass). Biological macromolecules are organic, meaning they contain carbon. In addition, they may contain hydrogen, oxygen, nitrogen, and additional minor elements.
3.1.1 Dehydration Synthesis Reactions
Most macromolecules are made from single subunits, or building blocks, called monomers. The monomers combine with each other using covalent bonds to form larger molecules known as polymers. In doing so, monomers release water molecules as byproducts. This type of reaction is known as dehydration synthesis (also known as condensation), which means “to make while losing water.”
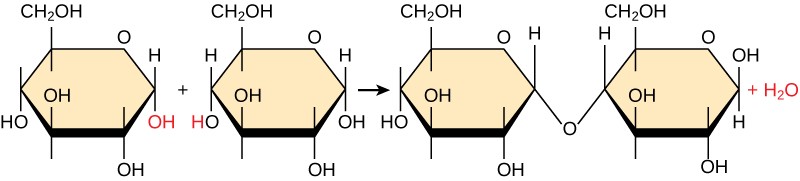
In a dehydration synthesis reaction, the hydrogen of one monomer combines with the hydroxyl group of another monomer, releasing a molecule of water (Figure 3.2). At the same time, the monomers share electrons and form covalent bonds. As additional monomers join, this chain of repeating monomers forms a polymer. Different types of monomers can combine in many configurations, giving rise to a diverse group of macromolecules. Even one kind of monomer can combine in a variety of ways to form several different polymers: for example, glucose monomers are the constituents of starch, glycogen, and cellulose.
3.1.2 Hydrolysis Reactions
Polymers are broken down into monomers in a process known as hydrolysis, which means “to split water.” (Figure 3.3). During these reactions, the polymer is broken into two components: one part gains a hydrogen atom (H+) and the other gains a hydroxyl molecule (OH–) from a split water molecule.
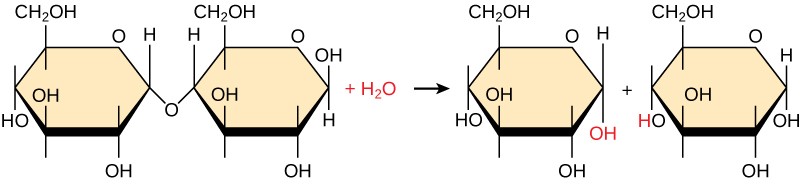
Dehydration and hydrolysis reactions are catalyzed, or “sped up,” by specific enzymes; dehydration reactions involve the formation of new bonds, requiring energy, while hydrolysis reactions break bonds and release energy. These reactions are similar for most macromolecules, but each monomer and polymer reaction is specific for its class. For example, in our bodies, food is hydrolyzed, or broken down, into smaller molecules by catalytic enzymes in the digestive system. This allows for easy absorption of nutrients by cells in the intestine. Each macromolecule is broken down by a specific enzyme. For instance, carbohydrates are broken down by amylase, sucrase, lactase, or maltase. Proteins are broken down by the enzymes pepsin and peptidase, and by hydrochloric acid. Lipids are broken down by lipases. Breakdown of these macromolecules provides energy for cellular activities.
3.2 | Types and Functions of Proteins
Learning Objectives
By the end of this section, you will be able to:
- Describe the functions proteins perform in the cell and in tissues.
Proteins are one of the most abundant organic molecules in living systems and have the most diverse range of functions of all macromolecules. They are all, however, polymers of amino acids, arranged in a linear sequence. Proteins may be structural, regulatory, contractile, or protective; they may serve in transport, storage, or membranes; or they may be toxins or enzymes. Each cell in a living system may contain thousands of proteins, each with a unique function. Their structures, like their functions, vary greatly.
Structural proteins make up the cytoskeleton inside cells and the scaffold outside of cells. They include the keratin of our skin and the collagen of our connective tissue. Contractile proteins include actin and myosin, which allow muscles to contract. Antibodies that help mount an immune response are proteins, as is hemoglobin, which transports oxygen in our blood. Cell membranes contain many proteins, including receptors, channels, and pumps, and many of the signaling molecules that bind to receptors, such as hormones, are proteins. Enzymes are proteins that catalyze biochemical reactions. The primary types and functions of proteins are listed in Table 3.1.
Table 3.1 Protein types and functions.
|
Type |
Examples |
Functions |
|
Digestive Enzymes |
Amylase, lipase, pepsin, trypsin |
Help in digestion of food by catabolizing nutrients into monomeric units |
|
Transport |
Hemoglobin, albumin |
Carry substances in the blood or lymph throughout the body |
|
Structural |
Actin, tubulin, keratin |
Construct different structures, like the cytoskeleton |
|
Hormones |
Insulin, thyroxine |
Coordinate the activity of different body systems |
|
Defense |
Immunoglobulins |
Protect the body from foreign pathogens |
|
Contractile |
Actin, myosin |
Effect muscle contraction |
|
Storage |
Legume storage proteins, egg white (albumin) |
Provide nourishment in early development of the embryo and the seedling |
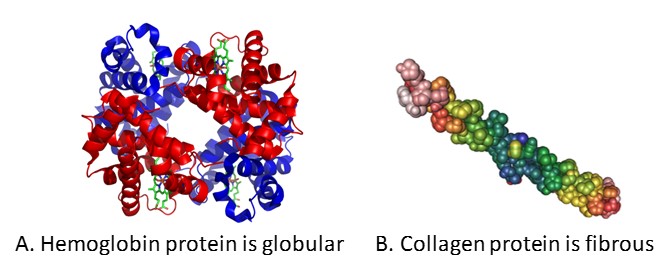
Reflecting their diverse functions, proteins have very diverse shapes and sizes. Some proteins, such as hemoglobin, are globular in shape whereas others, such as collagen, are fibrous (Figure 3.4). The shape of each protein is critical to its function, and this shape is maintained by many different types of chemical bonds. Changes in temperature, pH, and exposure to chemicals may lead to permanent changes in the shape of the protein, leading to loss of function, known as denaturation.
3.3 | Amino Acids
Learning Objectives
By the end of this section, you will be able to:
- Discuss the relationship between amino acids and proteins.
- Describe the structure of an amino acid.
- Understand the peptide bond.
Amino acids are the monomers that make up proteins. All proteins are made up of different arrangements of the same 20 amino acids. Each amino acid has the same fundamental structure, which consists of a central carbon atom bonded to an amino group (NH2), a carboxyl group (COOH), a hydrogen atom, and a variable “R” group (Figure 3.5). The name “amino acid” is derived from the presence of the amino group and the acidic carboxyl group.
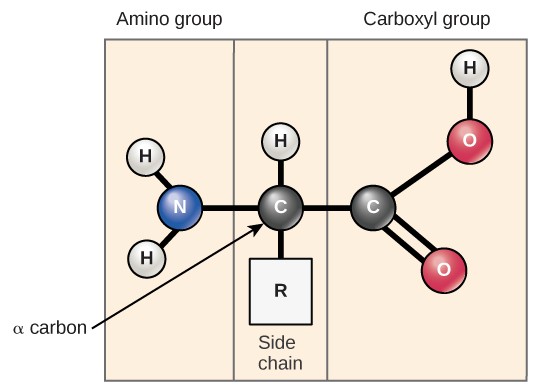
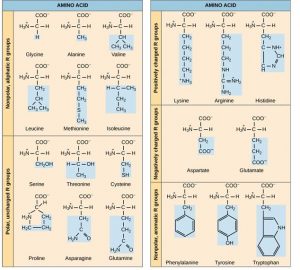
The same 20 common amino acids are present in proteins from all species of life. Ten of these are considered essential amino acids in humans because the human body cannot produce them and they must be obtained from the diet. Each amino acid differs only in the R group (or side chain). The chemical nature of the R group determines the nature of the amino acid (that is, whether it is acidic, basic, polar, or nonpolar). For example, amino acids such as valine, methionine, and alanine are nonpolar or hydrophobic in nature, while amino acids such as serine, threonine, and cysteine are polar and have hydrophilic side chains. The side chains of lysine and arginine are positively charged, while the side chains of aspartate and glutamate are negatively charged. (Figure 3.6).
Amino acids are linked together into linear chains called polypeptides. While the terms polypeptide and protein are sometimes used interchangeably, a polypeptide is technically a polymer of amino acids, whereas the term protein is a polypeptide or polypeptides that have a distinct shape and a unique function. The sequence and the number of amino acids determine the protein’s shape, size, and function. After protein synthesis (translation), most proteins are modified. Only after these modifications is the protein completely functional.
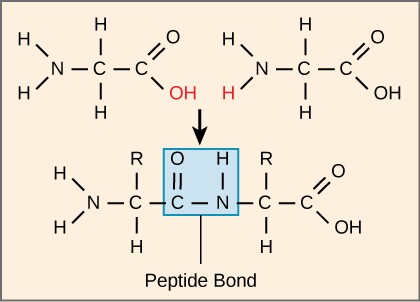
Each polypeptide has an N terminal, with a free amino group, and a C terminal, with a free carboxyl group. Amino acids are attached to other amino acids by covalent bonds, known as peptide bonds, which are formed by dehydration synthesis reactions. The carboxyl group of one amino acid and the amino group of the incoming amino acid combine, releasing a molecule of water and forming a peptide bond (Figure 3.7). Additional amino acids are always added to the C terminus until the chain is complete. The resulting polypeptide chain has a peptide backbone (or carbon-nitrogen backbone), that is identical for all proteins, with the variable R groups extending off of the backbone. Polypeptides differ from each other only in the order of the R groups.

The Evolutionary Significance of Cytochrome cCytochrome c is a protein that is important for cellular respiration. Sequencing the cytochrome c protein from different species has shown that there is a considerable amount of amino acid sequence homology among different species. Evolutionary kinship can be assessed by measuring the similarities or differences among various species’ DNA or protein sequences.Human cytochrome c contains 104 amino acids. 37 of these amino acids appear in the same position in samples of cytochrome c from a variety of different species. Human and chimpanzee cytochrome c is identical and human and rhesus monkey cytochrome c differ in only one amino acid. Surprisingly, human and yeast cytochrome c also differ in just one amino acid.
3.4 | Protein Structure
Learning Objectives
By the end of this section, you will be able to:
- Explain the four levels of protein organization.
- Describe the ways in which protein structure and function are linked.
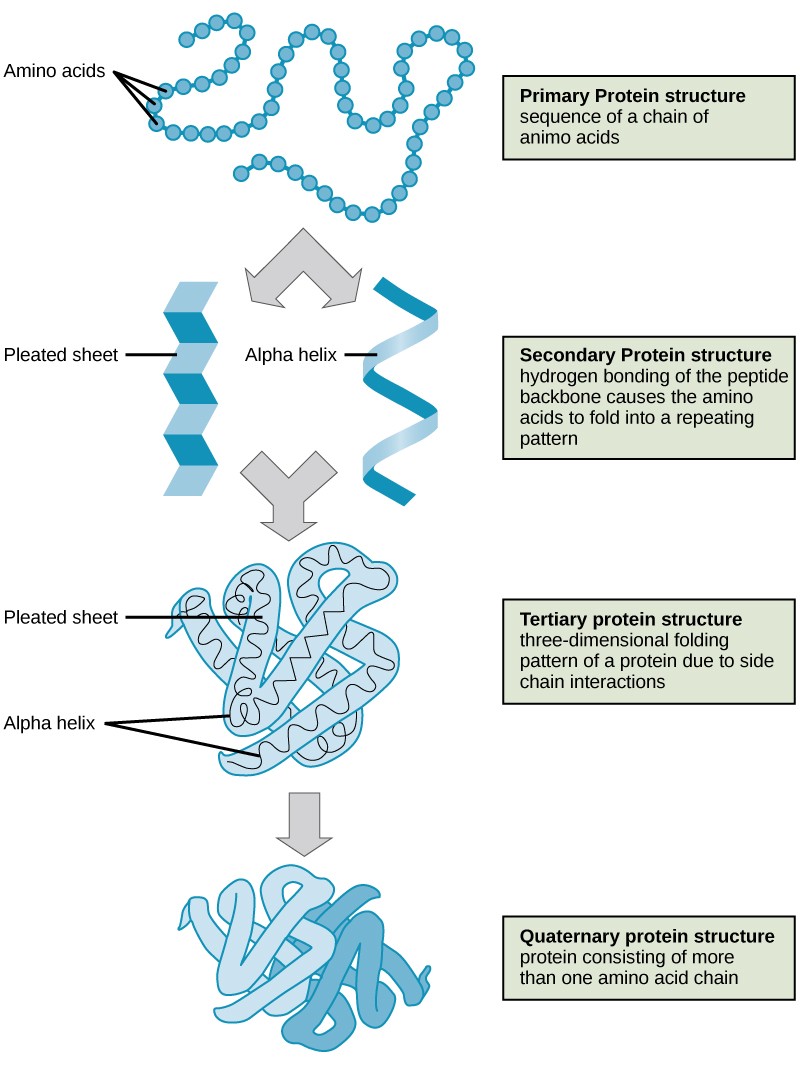
The structure of a protein is critical to its function. For example, an enzyme can bind to a specific substrate at a site known as the active site. If this active site is altered because of local changes or changes in overall protein structure, the enzyme may be unable to bind to the substrate. To understand how the protein gets its final shape or conformation, we need to understand the four levels of protein structure: primary, secondary, tertiary, and quaternary.
3.4.1 Primary Structure
The unique sequence of amino acids in a polypeptide chain is its primary structure. For example, the pancreatic hormone insulin has two polypeptide chains, A and B, which are linked together by disulfide bonds. The primary structure of each chain is indicated by three-letter abbreviations that represent the names and order of the amino acids. The N terminal amino acid of the A chain is glycine, whereas the C terminal amino acid is asparagine (Figure 3.8). The sequences of amino acids in the A and B chains are unique to insulin.
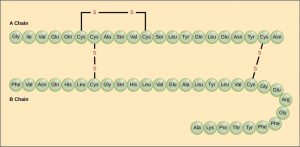
The amino acid cysteine (cys) has a sulfhydryl (SH) group as a side chain. Two sulfhydryl groups can react in the presence of oxygen to form a disulfide (S-S) bond. Two disulfide bonds connect the A and B chains together, and a third helps the A chain fold into the correct shape.
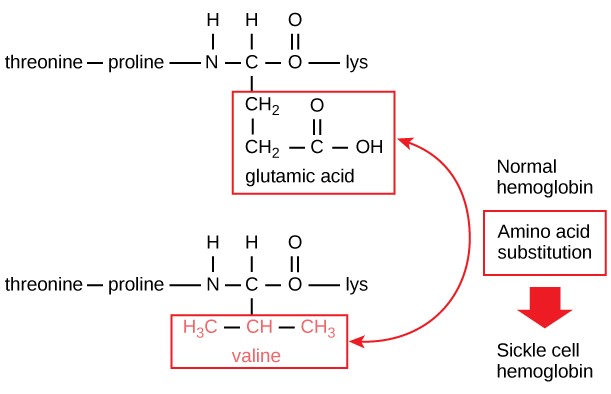
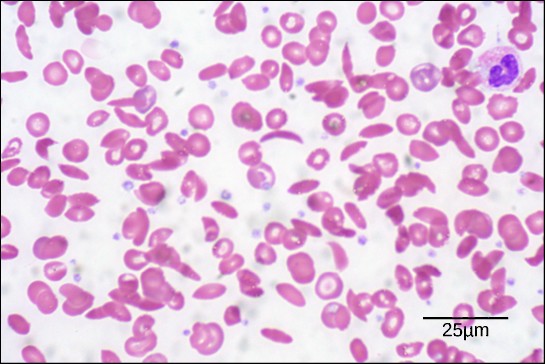
The unique primary sequence for every protein is determined by the gene that encodes the protein. Even a small change in a gene can lead to a different amino acid being added to the growing polypeptide chain. For example, in the human genetic disease sickle cell anemia, the hemoglobin β chain (a small portion of which is shown in Figure 3.9A) has a single amino acid substitution (valine for glutamic acid). This change of one amino acid in the chain causes hemoglobin molecules to form long fibers that distort red blood cells into a crescent or “sickle” shape, which clogs arteries and leads to serious health problems such as breathlessness, dizziness, headaches, and abdominal pain (Figure 3.9B).
3.4.2 Secondary Structure
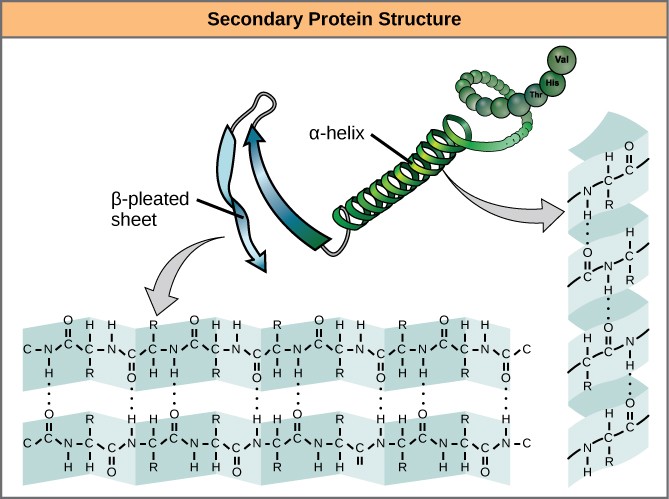
The local folding of the polypeptide in some regions gives rise to the secondary structure of the protein. The most common are the α-helix and β-pleated sheet structures (Figure 3.10). Both structures are formed by hydrogen bonds forming between parts of the peptide backbone of the polypeptide. Specifically, the oxygen atom in the carbonyl group in one amino acid interacts with another amino acid that is four amino acids farther along the chain.
3.4.3 Tertiary Structure
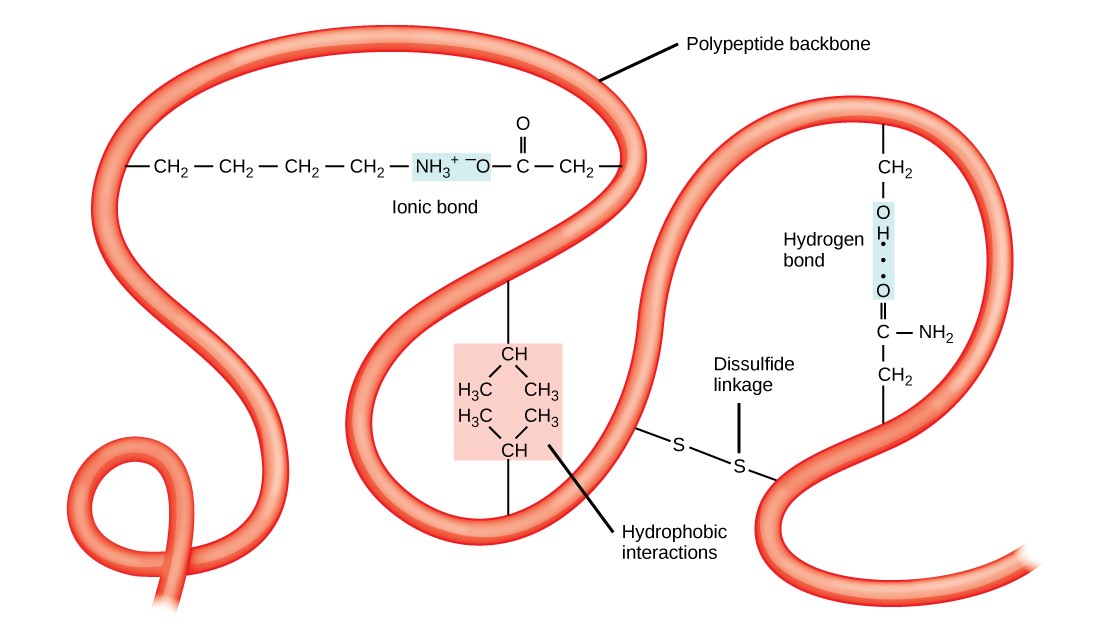
The unique three-dimensional structure of a polypeptide is its tertiary structure (Figure 3.11). This structure is primarily due to interactions among R groups. For example, R groups with like charges are repelled by each other and those with unlike charges are attracted to each other via ionic bonds. When protein folding takes place in a watery environment, such as that found inside cells, the hydrophobic R groups of nonpolar amino acids lay in the interior of the protein, while the hydrophilic R groups face out. Hydrophobic R groups also interact with each other through van der Waals forces.Interaction between cysteine side chains forms disulfide linkages, which are the only covalent bond formed during protein folding. All of these interactions determine the final three-dimensional shape of the protein. When a protein loses its three-dimensional shape, it may no longer be functional.
3.4.4 Quaternary Structure
In nature, some proteins are formed from several separate polypeptides, known as subunits. The interaction of these subunits forms the quaternary structure of a protein. Weak interactions between the subunits help to stabilize the overall structure. For example, silk is a fibrous protein that results from hydrogen bonding between different chains.
The four levels of protein structure (primary, secondary, tertiary, and quaternary) are illustrated in Figure 3.1.
3.4.5 Denaturation and Protein Folding
If a protein is subject to changes in temperature, pH, or exposure to chemicals, it may lose its shape, a process called denaturation. The primary structure of the protein is not changed by denaturation but some or all of the folding is lost. Denaturation is often reversible, allowing the protein to resume its function. Sometimes denaturation is irreversible, leading to permanent loss of function. One example of irreversible protein denaturation is cooking an egg white. Different proteins denature under different conditions. For example, bacteria from hot springs have proteins that function at temperatures close to boiling. Although stomach acid denatures proteins as part of digestion, the digestive enzymes of the stomach retain their activity under these conditions.
Correct folding of proteins is critical to their function. Although some proteins fold automatically, recent research has discovered that some proteins receive assistance in folding from protein helpers known as chaperones.
